A lot of teams meet PostgreSQL sharding the same way. Not in a design workshop, but during an outage review.
The app is working. Customer adoption is climbing. Product wants more features, sales wants larger accounts, and the database has steadily become the busiest employee in the company. Query latency gets uneven. A few write-heavy tables start attracting contention. Maintenance windows feel smaller every month. Engineers who should be shipping product are instead chasing slow statements, vacuum behavior, and replication lag.
That's the moment when database sharding in PostgreSQL starts showing up in architecture conversations.
It also tends to show up too early. Sharding is powerful, but it's not a cleanup tool for poor indexing, weak query design, or a schema that no longer matches how the application behaves. It's a structural change to how data is stored, routed, queried, migrated, backed up, and debugged. Once you cross that line, your team isn't managing one database system anymore. You're managing a distributed one.
Growing systems usually need a broader scaling lens first. Teams that are still evaluating strategies for cloud computing growth often find that the database problem is partly an application architecture problem, partly an operations problem, and only sometimes a true sharding problem.
Introduction The Scaling Challenge
A single PostgreSQL instance can carry a product surprisingly far. That's why many teams stay on a monolith longer than they expected.
At first, the signs look manageable. A dashboard query starts timing out under load. A hot tenant dominates one shared table. Bulk jobs collide with user traffic. Then you add caching, tune a few indexes, and buy more headroom. That works for a while.
Then the pattern changes.
When the database becomes the bottleneck
The problem isn't one bad query anymore. The whole shape of the workload starts pressing against a single machine. Reads, writes, storage, background maintenance, and operational tasks all compete for the same box. Even if the application is well-built, one primary node still has physical limits.
That's where sharding enters the picture. In practical terms, sharding means splitting data across multiple database servers so one system no longer carries the full dataset and the full traffic load.
A good sharding decision usually starts with one sentence: “We can't keep asking one server to do all of this.”
Why sharding feels attractive and why it's risky
Sharding promises horizontal scale. Instead of stretching one machine upward, you spread data and work across multiple machines. For the right workload, that's the only sustainable answer.
But the cost is real. You add routing logic, data placement rules, migration complexity, and a new class of query behavior. A design that looked simple in a monolith can become expensive once data lives on different nodes. Teams often underestimate that shift.
The right question isn't “Can PostgreSQL be sharded?” It can. The better question is whether your current pain justifies the operational weight that comes with it.
When to Consider Sharding Your PostgreSQL Database
Several cheaper fixes should be attempted before sharding anything.
Independent guidance recommends trying indexing, query tuning, read replicas, partitioning, denormalization, and materialized views before sharding, because those options can be cheaper and faster to implement. It also frames the decision with the right question: “How far can I get without sharding, and what evidence tells me I've crossed the line?” (Lazer Technologies on what to try before sharding)
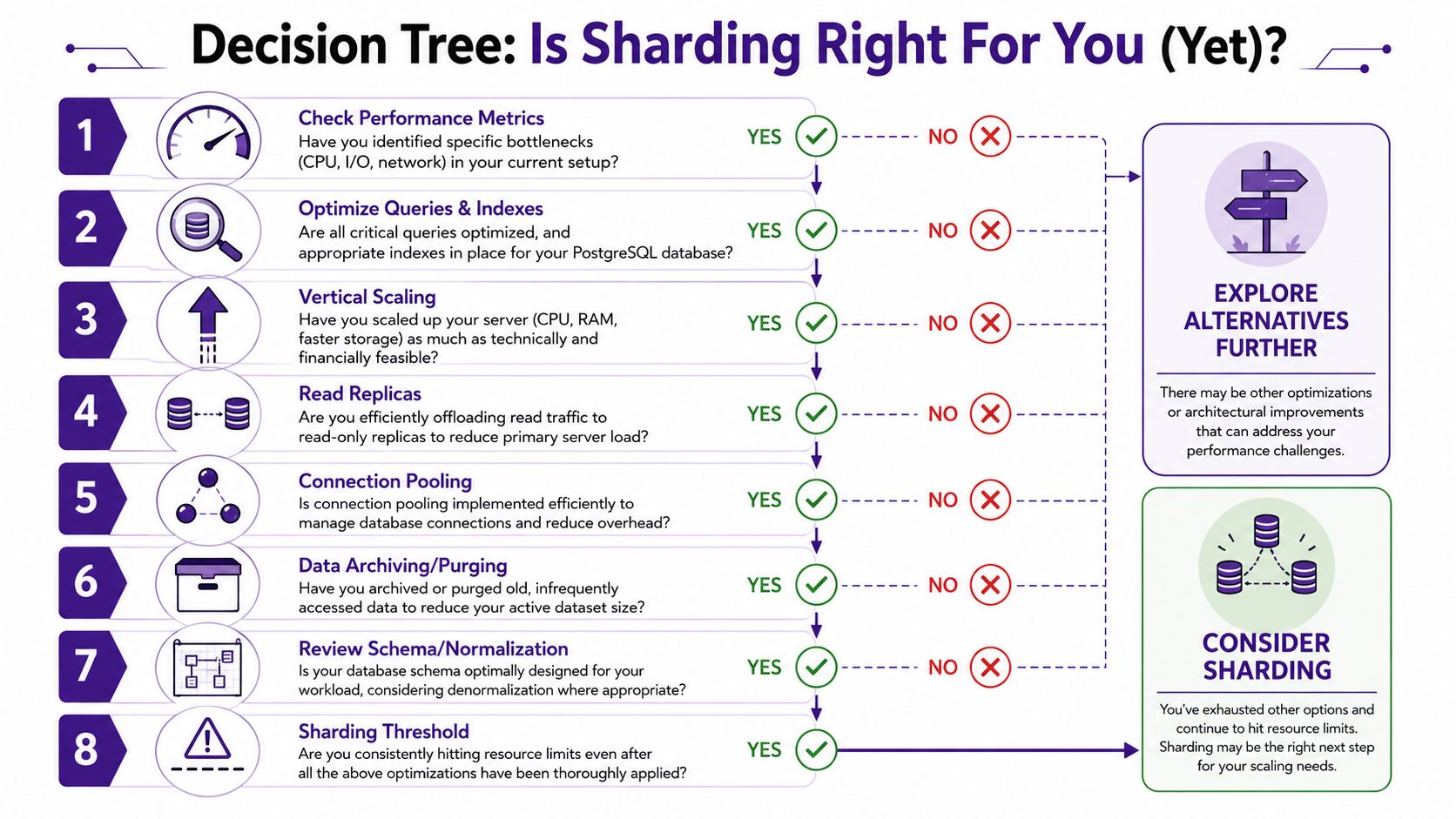
What to exhaust first
If your team hasn't worked through the basics with discipline, sharding is premature.
- Tune the expensive queries: Start with the statements that drive the highest load or the worst tail latency. Fix access paths, remove avoidable scans, and check whether the query shape matches the indexes you have.
- Improve indexing deliberately: Teams often add indexes reactively and end up with a bloated set that helps some reads while hurting writes. Index review is maintenance, not a one-time task.
- Offload reads: Read replicas are often the fastest way to remove pressure from a primary when the read/write mix is lopsided.
- Use native partitioning where it fits: Large append-heavy or time-based tables often become easier to manage with partitioning even if you never shard them across servers.
- Revisit schema and data lifecycle: Archiving old rows, denormalizing carefully, or materializing expensive summaries can remove a surprising amount of pain.
If your team is still formalizing fundamentals, a practical primer on how to create a database can help reset the discussion around schema, access patterns, and operational design before you jump to distributed architecture.
Signals that point to real sharding pressure
Sharding starts to make sense when the bottleneck is structural, not accidental.
A few examples:
| Situation | Better first move | When sharding becomes credible |
|---|---|---|
| Read traffic overload | Replicas, caching, query tuning | Reads are handled, but write pressure and storage still hit one primary |
| One giant table hurts maintenance | Partitioning, archiving | The workload still exceeds what one machine can own |
| Tenant isolation problems | Schema redesign, hotspot mitigation | Large tenants need data and compute spread across separate nodes |
| Growth in both data and writes | Vertical scaling, tuning | You've outgrown the “bigger box” model |
The threshold is about evidence
You should be able to say, with confidence, that your team has already done the straightforward work. Not casually. Thoroughly.
Practical rule: If you can't explain why indexing, query tuning, read replicas, partitioning, and schema changes won't solve the problem, you're not ready to shard.
The strongest reasons to shard PostgreSQL are usually some combination of these:
- A single node can't carry the write workload anymore
- Storage growth makes one-instance operations too heavy
- Large tenants or domains need to be separated across machines
- Your access pattern naturally supports data locality by key
If you don't have those conditions, sharding may only replace one bottleneck with a more complicated one.
Core Sharding Concepts Explained
The easiest way to explain sharding is to stop thinking about servers and start thinking about shelves.
A monolithic database is one massive library building. Every book is in the same place. That's convenient until too many people arrive, the shelves get crowded, and every librarian works the same checkout desk. Sharding means splitting that library across multiple branches while keeping a shared catalog so visitors still feel like they're using one system.
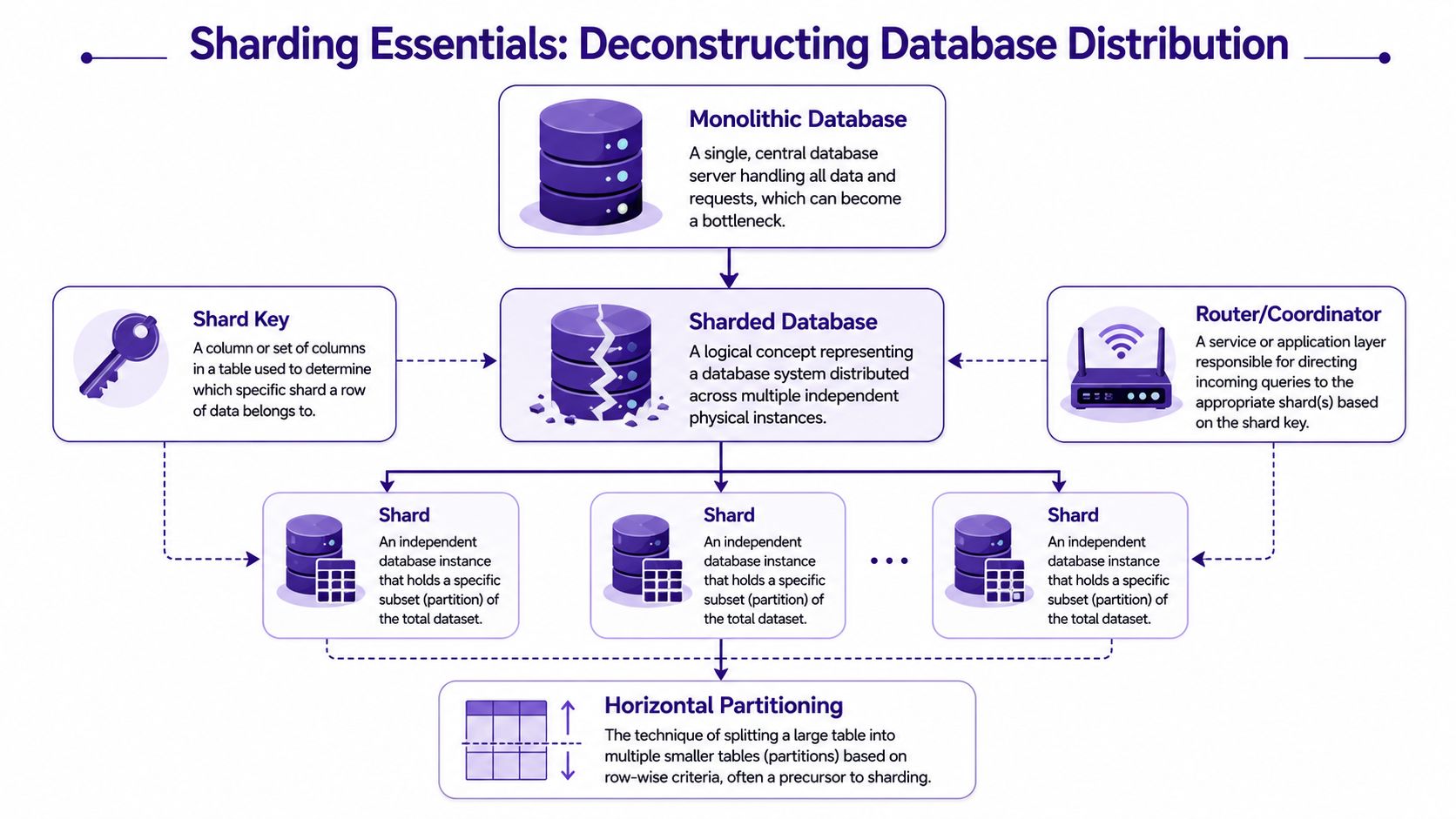
The key terms that matter
A shard is one independent database instance that holds only part of the total data.
A shard key is the rule used to decide where each row belongs. If your application is multi-tenant, that key is often something like account, workspace, customer, or organization. If the key is chosen well, related data tends to land together.
A router or coordinator is the traffic cop. It receives a query and decides which shard should handle it. Sometimes that logic lives in the application. Sometimes it lives in middleware or a PostgreSQL-based routing layer.
Horizontal partitioning versus vertical partitioning
People mix these up, and the distinction matters.
- Horizontal partitioning: Split rows across locations. One shard gets some customers, another shard gets others.
- Vertical partitioning: Split columns or functions. One service owns billing data, another owns content metadata.
Sharding in PostgreSQL is about horizontal partitioning. You're distributing rows of a dataset across multiple servers.
For teams that think carefully about search, metadata, and organization, this mental model has a close parallel to document indexing concepts. The success of both depends on choosing organizing keys that reflect how people retrieve information.
Why colocated data matters
Good sharding tries to keep data that is queried together on the same shard. That's called colocation.
Suppose most requests in your app load a tenant, its users, its projects, and its permissions together. If those rows all share the same shard key and land on the same shard, the query stays local. If they're scattered, the router has to coordinate across nodes. That's slower, harder to debug, and more fragile under load.
Cross-shard joins are the distributed systems version of a short commute turning into an airport connection.
What the application feels
From the application's point of view, the ideal sharded system still behaves like one logical database. That's the trick. Physically distributed, logically coherent.
When that illusion holds, engineers stay productive. When it breaks, every feature starts carrying hidden database placement concerns. That's why core concepts matter more than they seem. Most painful sharding stories aren't caused by PostgreSQL syntax. They're caused by weak data placement decisions.
PostgreSQL Sharding Architectures and Tools
PostgreSQL gives you several paths toward sharding, and they sit on a spectrum from manual control to heavier abstraction.
The first thing to keep straight is this: native partitioning and true multi-server sharding are related, but they aren't the same thing. Partitioning inside one PostgreSQL instance can solve real problems on its own. Sharding starts when those partitions or data domains live across multiple servers.
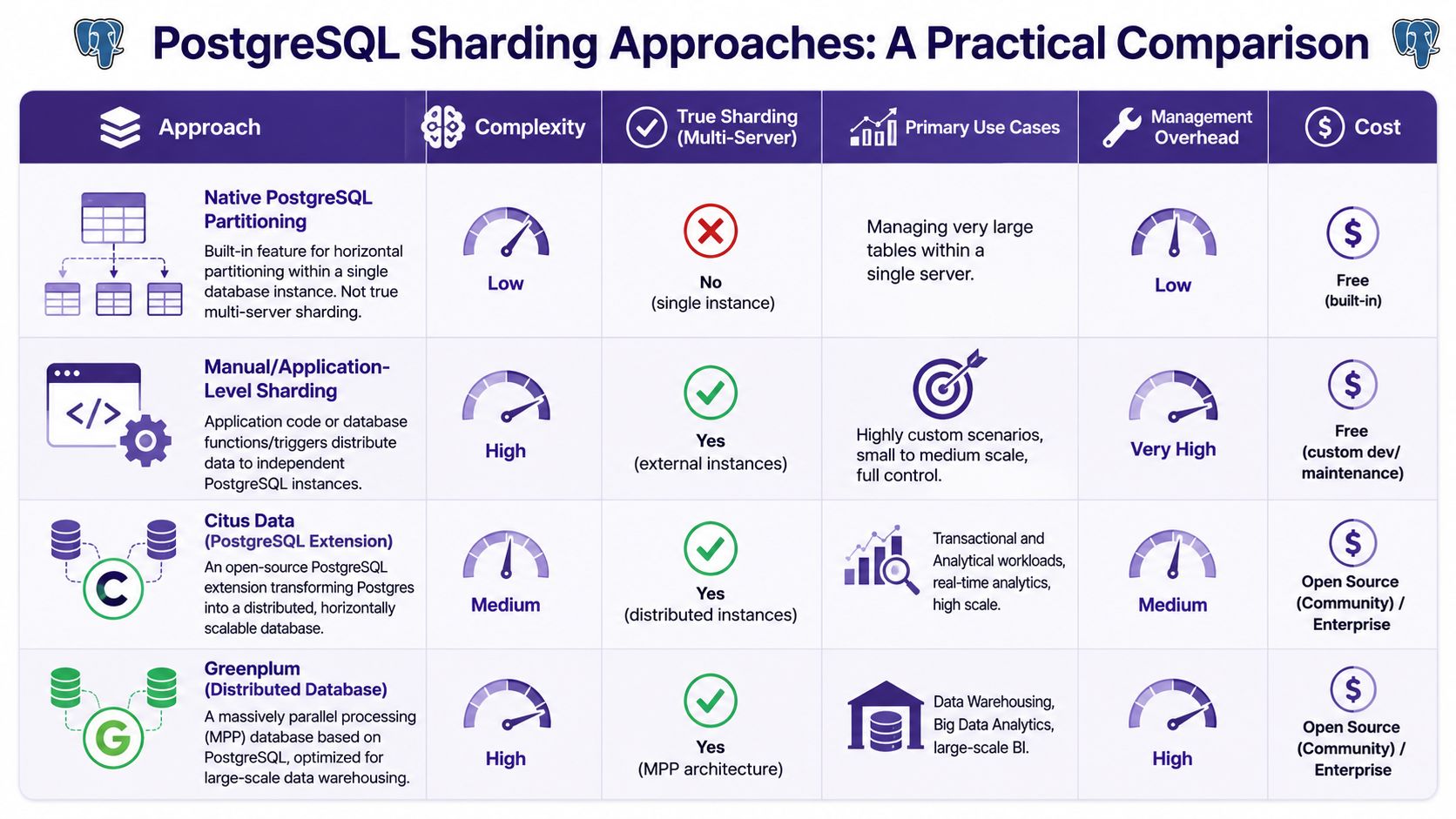
Native PostgreSQL plus FDW
A major milestone in PostgreSQL's sharding story came from the core platform itself. PostgreSQL 10 introduced declarative table partitioning, and PostgreSQL 11 added remote partition insertion, which made it possible to shard a single partitioned table across multiple PostgreSQL servers using Foreign Data Wrappers, without changing application logic for every insert path (PgDash on PostgreSQL 11 sharding).
This approach appeals to teams that want control.
You can model a parent partitioned table, place real partitions on foreign servers, and let PostgreSQL treat the whole thing as one logical table. With the right design, applications keep talking to the parent while the data lives elsewhere.
What works well
- You stay close to standard PostgreSQL primitives.
- You control placement, routing shape, and rollout strategy.
- It fits teams that already have strong database engineering skills.
What doesn't
- You own more of the operational behavior.
- Query design matters a lot more.
- Rebalancing and schema changes across shards require discipline.
Manual or application-level sharding
Some teams don't want the database layer to hide distribution at all. They choose a shard key, compute destination in the application, and connect directly to the right PostgreSQL server.
This model gives maximum clarity and maximum responsibility.
It works best when the application already has a strong tenant boundary and engineers are comfortable exposing shard awareness in service code. It works poorly when lots of queries need to act globally, because application-level fan-out is hard to keep clean over time.
Distributed extensions and platforms
Tools like Citus are popular because they reduce the amount of custom plumbing teams have to build. Instead of stitching together routing, placement, and distributed query behavior by hand, you adopt a PostgreSQL distribution model that handles much of it for you.
That convenience comes with design constraints. Extensions and platforms usually reward certain access patterns and punish others. If your workload fits the tool's model, adoption is much smoother. If it doesn't, you can spend a lot of time fighting the abstraction.
Greenplum sits in a different lane. It's based on PostgreSQL but oriented more toward large-scale analytical and warehousing workloads than the typical transactional app.
A practical comparison
| Approach | Best fit | Main advantage | Main drawback |
|---|---|---|---|
| Native partitioning only | Large tables on one server | Low complexity | Not true multi-server sharding |
| FDW-based sharding | Teams wanting PostgreSQL-native control | Flexible and transparent | High operational ownership |
| Application-level sharding | Strong tenant isolation in app design | Full routing control | Code complexity spreads fast |
| Distributed extension | Teams wanting more automation | Faster path to distributed behavior | Less flexibility outside the tool's model |
The right tool isn't the one with the most features. It's the one your team can operate at 2 a.m. during an incident.
Designing Your Sharding Strategy
Sharding decisions tend to look obvious in hindsight and expensive in production. By the time a team is here, the easy scaling options should already be under pressure: query tuning, indexing, partitioning, read replicas, bigger hardware, cache layers, and workload isolation. That matters because the shard plan you choose will shape application code, operations, and incident response for years.
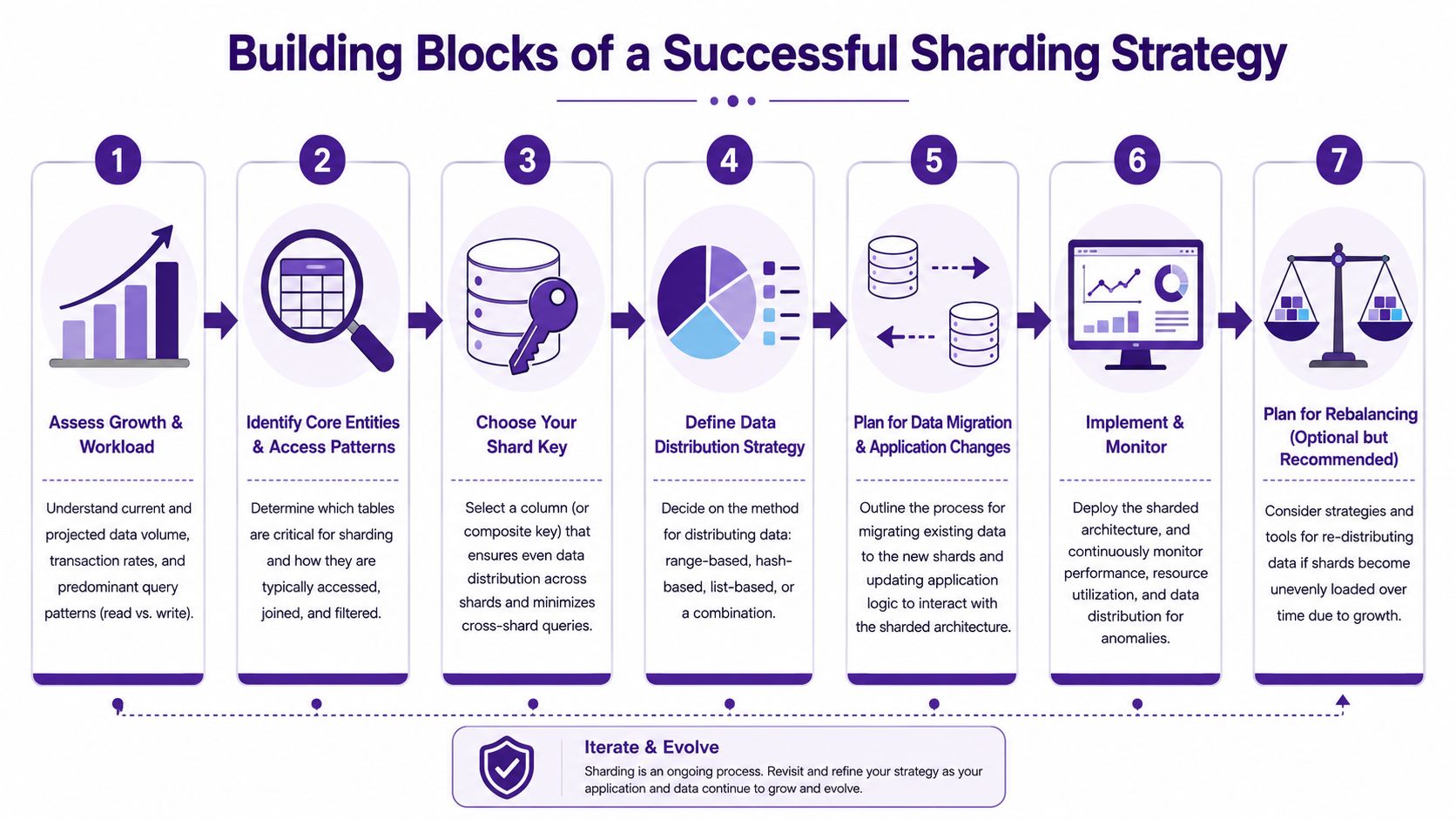
Start with request flow, not table size
Large tables create pressure, but they do not tell you how to shard. Request paths do.
A shard key should follow the way the application reads and writes data. In many SaaS systems, that means starting with the tenant, organization, workspace, or account that owns the request. If the common path for a user action begins with tenant context, keeping that tenant's hot data together usually gives better latency and fewer cross-shard joins.
This is why teams that shard successfully spend time tracing a handful of important requests end to end. They map the lookup path, the write path, and the joins each request needs. That exercise often reveals a hard truth: some workloads are poor candidates for sharding, or at least poor candidates right now.
A strong shard key usually does four things:
- Matches the dominant access pattern: Route requests using information the application already has at the start of the call.
- Keeps related rows together: Local joins are cheaper, simpler, and easier to reason about during incidents.
- Spreads hot traffic well enough: Perfectly even distribution is less important than avoiding obvious write hotspots.
- Stays stable over time: If the key changes often, data movement becomes part of normal application behavior.
Design for the queries you cannot afford to slow down
The fastest way to regret a shard key is to choose one that looks mathematically tidy but forces your most important requests to touch multiple shards.
Cross-shard reads are not just slower. They are harder to cache, harder to debug, and harder to recover during partial failure. A distributed system works like a restaurant with several kitchens and one front desk. If every order needs coordination across all kitchens, tickets back up. If most orders stay in one kitchen, service remains predictable.
That is the bar to aim for. The goal is not evenly scattering rows across machines. The goal is keeping the expensive, frequent, user-facing work local whenever possible.
Questions to pressure-test the shard key
Before committing, answer these questions with real queries and production traces, not guesses:
- What request starts the majority of user activity?
- Which joins must remain local to hit your latency target?
- Which reads can tolerate fan-out across shards, and how often do they happen?
- Which customers or tenants are likely to become much larger than the rest?
- How will you move a large tenant later if one shard gets crowded?
- What happens to unique constraints, foreign keys, and transactional workflows once data is split?
The operational challenge starts here, not during migration. A shard key is a product decision as much as a database decision.
Plan for imbalance before it hurts
Even a good key can age badly. One enterprise customer signs, usage clusters in one region, or a new feature shifts traffic onto a narrow slice of data.
For that reason, a usable sharding strategy includes a rebalancing story from the start. Some teams use consistent hashing to make redistribution less disruptive. Others prefer explicit tenant placement because it gives more control over noisy neighbors and large-account isolation. The right answer depends on your workload and your team's ability to run placement changes safely under pressure.
This is also where engineering process matters. Rebalancing touches database operations, application routing, customer support, and rollout planning. Teams that already run disciplined change management usually handle this better, especially if they treat it like project management for software teams instead of a one-off database task.
What works in practice
Sharding around a natural ownership boundary usually holds up best. Multi-tenant SaaS products often have one. Collaboration systems often do too. Users, organizations, workspaces, and accounts are common examples because the application already uses them to authorize, query, and display data.
What fails more often is a key chosen for distribution alone. Even spread looks good in a diagram. Locality usually matters more in production.
Design check: If a high-value request needs cross-shard coordination by default, reconsider the shard key before you build the rest of the system.
Migrating to a Sharded Architecture
A sharding migration is where teams find out whether they needed sharding badly enough to justify it.
Creating shard tables, routing rules, and new connection paths is straightforward compared with moving a live system without breaking trust. The hard part is keeping writes correct while old and new paths overlap, proving that reads still behave the same way, and giving operators a rollback path they can use under pressure. This is why I treat sharding as a last resort. If vertical scaling, partitioning, read replicas, query work, or denormalization can buy enough time, they are usually cheaper than this migration.
Teams that do shard successfully tend to follow the same pattern: double-writes, historical backfill, verification, then cutover. As noted earlier, public writeups from companies that have done this at scale point to the same lesson. The difficult work is consistency during data movement, not the mechanics of creating shards.
A practical migration often looks like this:
Start with double-writes
Send each write to the current database and the target shard. Keep the application response rules explicit so operators know what happens if one write succeeds and the other fails.Backfill older data in controlled batches
Historical rows need to be copied without overwhelming replicas, saturating WAL, or starving production traffic. Batch size, retry behavior, and idempotency matter more than raw speed.Verify behavior, not just counts
Row counts can match while the application is still wrong. Check record-level correctness, foreign key relationships where they still exist, derived data, and the queries that drive real user flows.Cut reads over in stages
Start with low-risk traffic, internal users, or a single tenant class. Full cutover is safer when routing has already been exercised under real load.Keep rollback simple enough to use
A rollback plan that depends on manual heroics at 2 a.m. is not a plan. Keep the old path viable until the new one has earned trust.
Each phase fails in a different way. Double-writes introduce drift. Backfills race with live updates. Verification misses edge cases unless someone designs it around actual application behavior. Cutover exposes hidden fan-out queries, stale caches, and assumptions that only held when all data lived on one primary.
That is why the migration needs one operating plan shared by application engineers, DBAs, SREs, and support. A disciplined approach to project planning for software teams helps because this work spans code rollout, data operations, customer impact, and incident response.
A few habits make the migration less risky:
- Migrate one ownership boundary at a time: Pick the cleanest tenant or domain slice first.
- Use shadow reads before full cutover: Compare old and new results discreetly before users depend on the new path.
- Record every exception path: One-off scripts and manual fixes become long-term operational debt if nobody tracks them.
- Assign named owners: One person owns reconciliation, one owns routing, and one owns the go or no-go call during cutover.
Keep the migration boring. Do not pair it with a service decomposition, a major schema redesign, and a new cache strategy in the same release window. Sharding already expands the failure surface. Extra changes make it harder to isolate what went wrong.
The true test comes after the first cutover. Data distribution will drift, heavy tenants will appear, and a placement decision that looked balanced six months ago may stop working. A migration plan should leave behind tooling for reconciliation and movement later, not just scripts that get you through launch week.
Conclusion Living with a Sharded Database
A sharded PostgreSQL system can give a growing application room to keep moving. It can spread storage, isolate workload, and remove the hard ceiling that comes with one oversized primary.
It also changes daily operations.
Backups become coordinated. Monitoring becomes distributed. Troubleshooting becomes less intuitive because “the database” is no longer one place. Query behavior depends more heavily on data placement. Routine tasks like schema changes, consistency checks, and incident response need stronger process than they did before.
That's why the best sharding decision is often a restrained one. Try the simpler fixes first. Use partitioning, replicas, indexing, query tuning, denormalization, and materialized views where they fit. If those options stop being enough, then sharding becomes a strategic move instead of a panic response.
PostgreSQL gives teams credible ways to do this, from FDW-based designs built on core features to more automated distributed approaches. But none of those tools can rescue a weak shard key or a rushed migration. The teams that do this well are disciplined about workload analysis, ruthless about access patterns, and patient about rollout.
Sharding isn't magic. It's architecture with a long tail.
Handled well, it lets PostgreSQL keep serving an application long after a single node would've run out of road.
If your team also has to make sense of a growing body of technical docs, research notes, episodes, articles, and internal knowledge while you scale systems and workflows, Contesimal is worth a look. It helps organizations organize large content libraries, collaborate with AI in a structured way, and turn existing knowledge into more useful, searchable, reusable assets.